Stokastisk variabel og normalfordeling
En stokastisk variabel er en tilfældig variabel, der kan antage forskellige værdier med en vis sandsynlighed. Lad os sige, at vi slår med to terninger. Det samlede antal øjne på de to terninger kan man betegne med X som en stokastisk variabel. Den stokastiske variabel X kan antage værdierne fra 2 til 12. P(X=xi) er en betegnelse for sandsynligheden for, at den stokastiske variabel antager værdien xi. Med 2 terninger er der 36 mulige slag, men kun et af slagene giver i f.eks. alt 12 øjne, så P(X=12)=1/36.
Optimer dit sprog - Læs vores guide og scor topkarakter
Sådan bruger du materialet
Generel sandsynlighedstabel for en stokastisk variabel:

Eksempel: Sandsynlighedstabel for kast med to terninger:

Normalfordeling er en bestemt sandsynlighedsfordeling og er ofte brugt til at beskrive forskellige fænomener, herunder højder, vægt, karakterer, osv. Normalfordelingen er karakteriseret ved, at de fleste observationer er centreret omkring gennemsnittet, f.eks. karaktererne 4 og 7, og færre observationer findes, jo længere væk man kommer fra gennemsnittet.
Middelværdi og spredning
En normalfordeling er altid kendetegnet ved en middelværdi og en spredning. Man bruger ofte notationen N(μ,σ), som betegner en normalfordeling med middelværdien μ og spredningen σ.
Middelværdien/gennemsnittet beskriver den værdi, som de fleste udfald vil være tæt på, og spredningen er et mål for, hvor langt udfaldene spreder sig fra gennemsnittet.
Tæthedsfunktion og Fordelingsfunktion
For at forstå normalfordeling bedre, introducerer vi nu begreberne tæthedsfunktion og fordelingsfunktion.
Tæthedsfunktionen beskriver sandsynligheden for, at stokastiske variabler antager en bestemt værdi. Værdien aflæses på x-aksen og sandsynligheden aflæses på y-aksen. I en normalfordeling er tæthedsfunktionen en klokkeformet kurve, med toppunkt ved gennemsnittet. En høj spredning giver en lav, bred klokke, imens en lille spredning giver en høj smal klokke. Tæthedsfunktionen er givet ved forskriften
$$f(x)=1/(\sqrt{2π}⋅σ) e^(-1/2 ((x-μ)/σ)^2 )$$
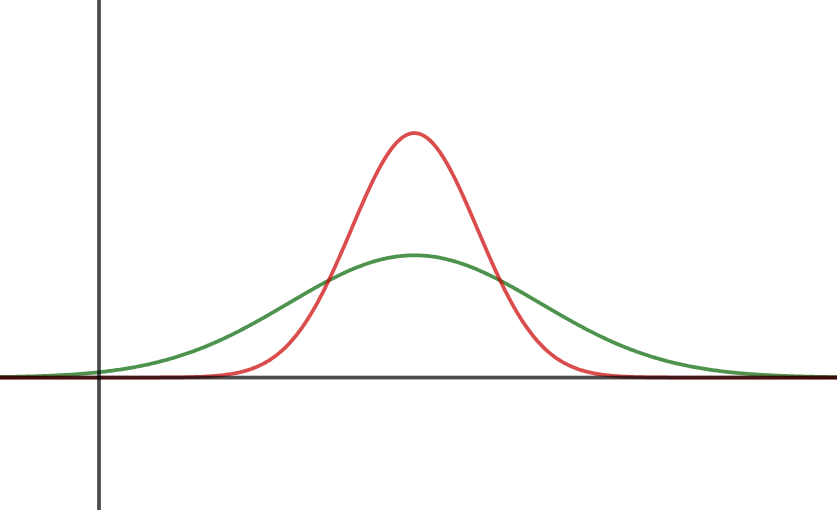
Sandsynlighed, fraktiler og kvartiler
Når vi arbejder med normalfordelingen, er vi ofte interesserede i sandsynligheder. For eksempel kan vi være interesseret i at finde sandsynligheden for, at et tilfældigt slag med to terninger giver mere en 8 øjne.
Fraktiler og kvartiler er begreber for at inddele dataene. Hvis man for eksempel er interesseret i 10%-fraktilen så er man interesseret i den værdi som 10% af dataene vil være mindre end eller lig med.
Kvartilerne er et begreb for at inddele dataene i fire lige store dele (kvarte). Man kalder også dette for kvartilsættet. Første kvartil er det samme som 25%-fraktilen, anden kvartil er det samme som medianen eller 50%-fraktilen, og tredje kvartil er det samme som 75%-fraktilen. For normalfordeling er medianen og middelværdien altid det samme, da fordelingen er symmetrisk omkring gennemsnittet.
Normale og exceptionelle udfald
I normalfordeling taler man om normale udfald, når et udfald er maksimalt to spredninger fra middelværdien.
Der er tale om et exceptionelt udfald, når et udfald er mere end 3 spredninger fra middelværdien.
For en normalfordelt stokastisk variabel med spredning σ og middelværdi μ gælder der desuden altid følgende sandsynligheder.
- P(μ-σ≤X≤μ+σ)=68,27%
- P(μ-2σ≤X≤μ+2σ)=95,45% (alle normale udfald)
- P(μ-3σ≤X≤μ+3σ)=99,73% (alle ikke-exceptionelle udfald)
Standardnormalfordelingen.
Standardnormalfordelingen er en særlig type normalfordeling, hvor gennemsnittet er 0, og spredningen er 1, hvilket kan skrives som N(0,1).
Tæthedsfunktionen er generelt givet ved
$$f(x)=1/(√2π⋅σ)⋅e^(-1/2 〖⋅((x-μ)/σ)〗^2 )$$
Tilnærmelsesvis normalfordeling
Når vi har store mængder data, kan vi nogle gange antage, at fordelingen er tilnærmelsesvis normal, selvom den måske ikke er præcist normalfordelt. I realiteten er det svært at foretage undersøgelser i den virkelige verden, hvor resultaterne er nøjagtigt normalfordelt. Derfor arbejder man ofte med tilnærmelsesvis normalfordeling. Dette er nyttigt, fordi normalfordelingen har mange matematiske egenskaber, der gør det nemt at foretage analyser og beregninger.

Skriv et svar